1.0完成了统计学模型、torch二分类,但与业界(网易游戏)前沿有差距,预期3|4泛化调研,5月份确定方案
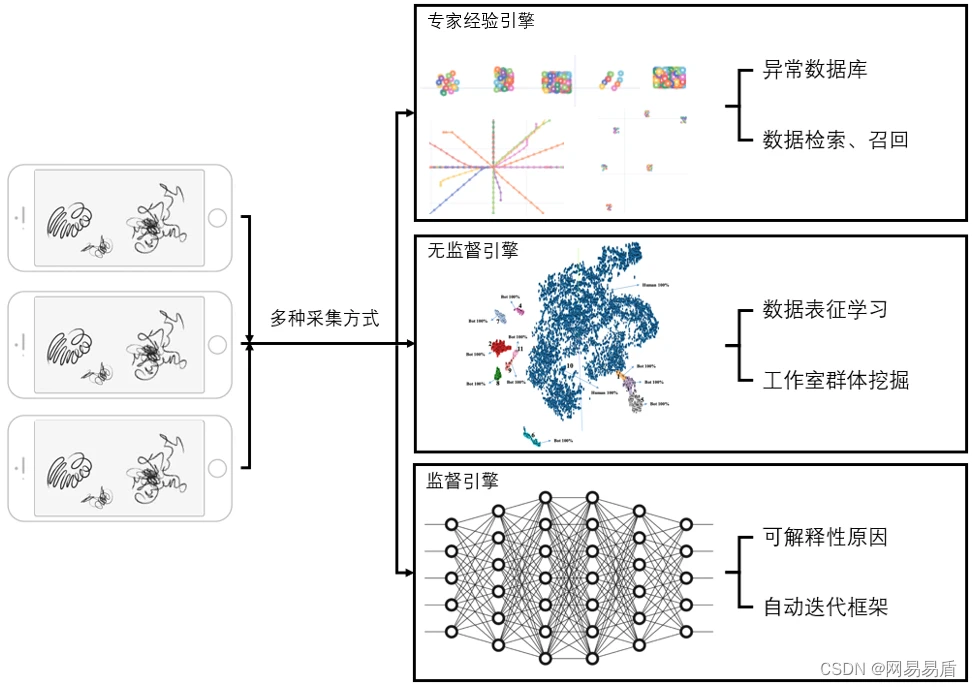
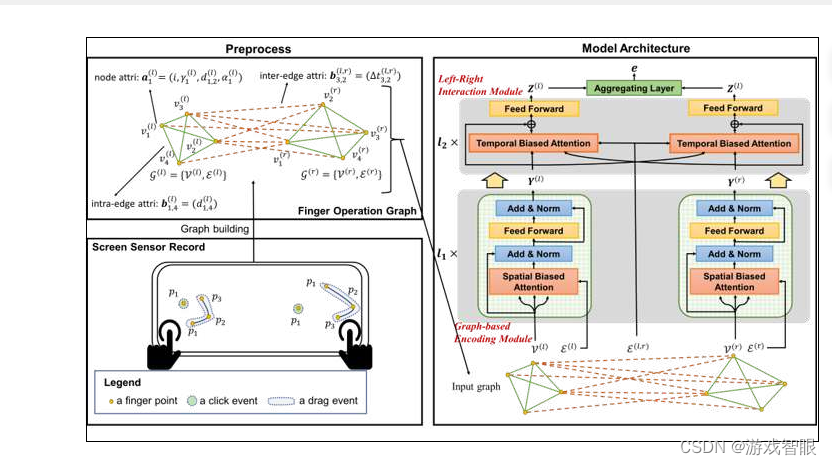
方案拟定:统计学特征增加(概率分布)|熵编码训模型|数据点绘图->图算法
1. 基于统计特征
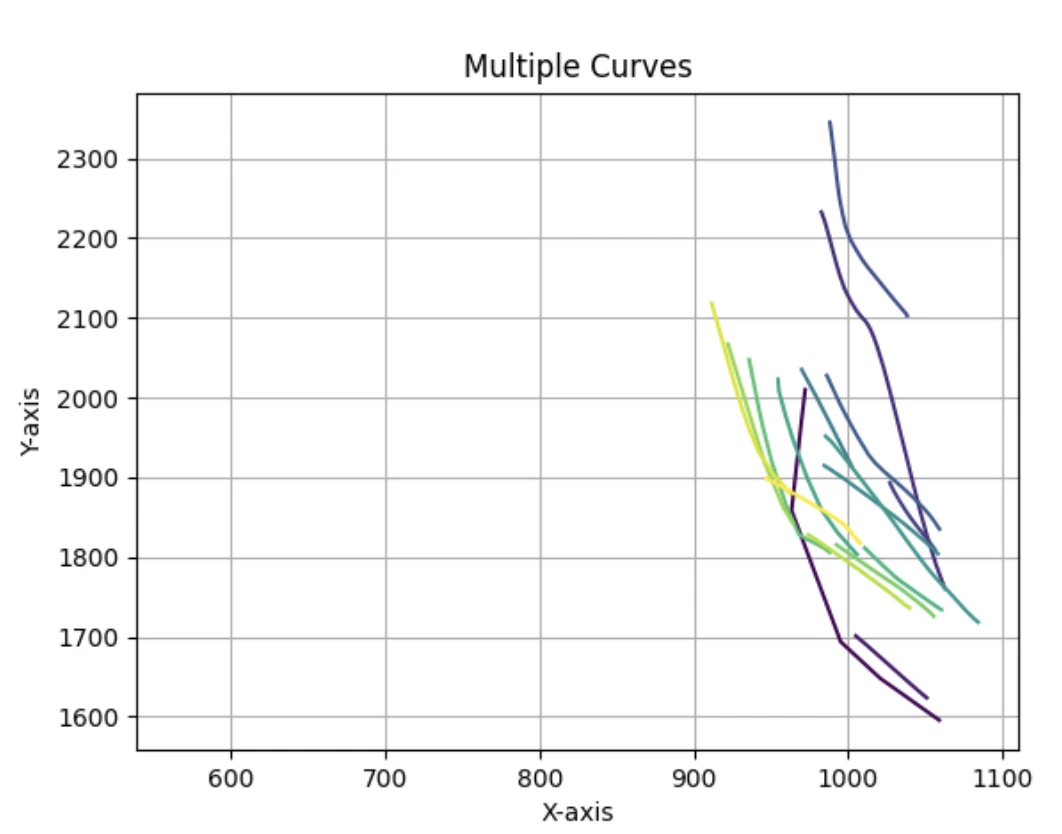
速度、加速度、时间间隔、轨迹形状、三线夹角、点分布、左右手
2. 机器学习与深度学习
随机森林分类器:可以使用 scikit-learn 库中的随机森林算法,通过提取轨迹数据的特征(如速度、加速度、时间间隔等)进行训练和分类。
LSTM(长短期记忆网络:由于轨迹数据是时间序列数据,LSTM能够很好地捕捉时间序列中的长期依赖关系,适用于区分真实轨迹和伪造轨迹。
XGBoost模型:通过计算轨迹数据的特征向量,并输入到XGBoost模型中进行训练和预测,可以有效识别伪造轨迹。
3. 基于图结构数据的方法
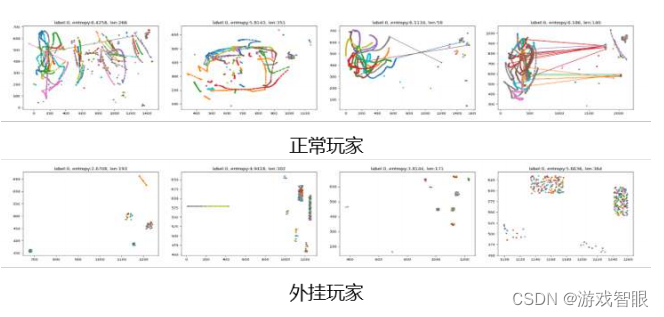
利用图结构数据和图学习技术,可以捕捉轨迹之间的关联特征.轨迹图转成3通道的二值化的图像,然后用图像分类模型,比如resnet、vgg,可以较好实现重合、相似计算。
4. 数据编码的方法
5. 实现记录
5.1 轨迹分析脚本
2.0优先构建可视化能力,用于分析和可解释性
速度、加速度、角度、点间耗时等绘制概率分布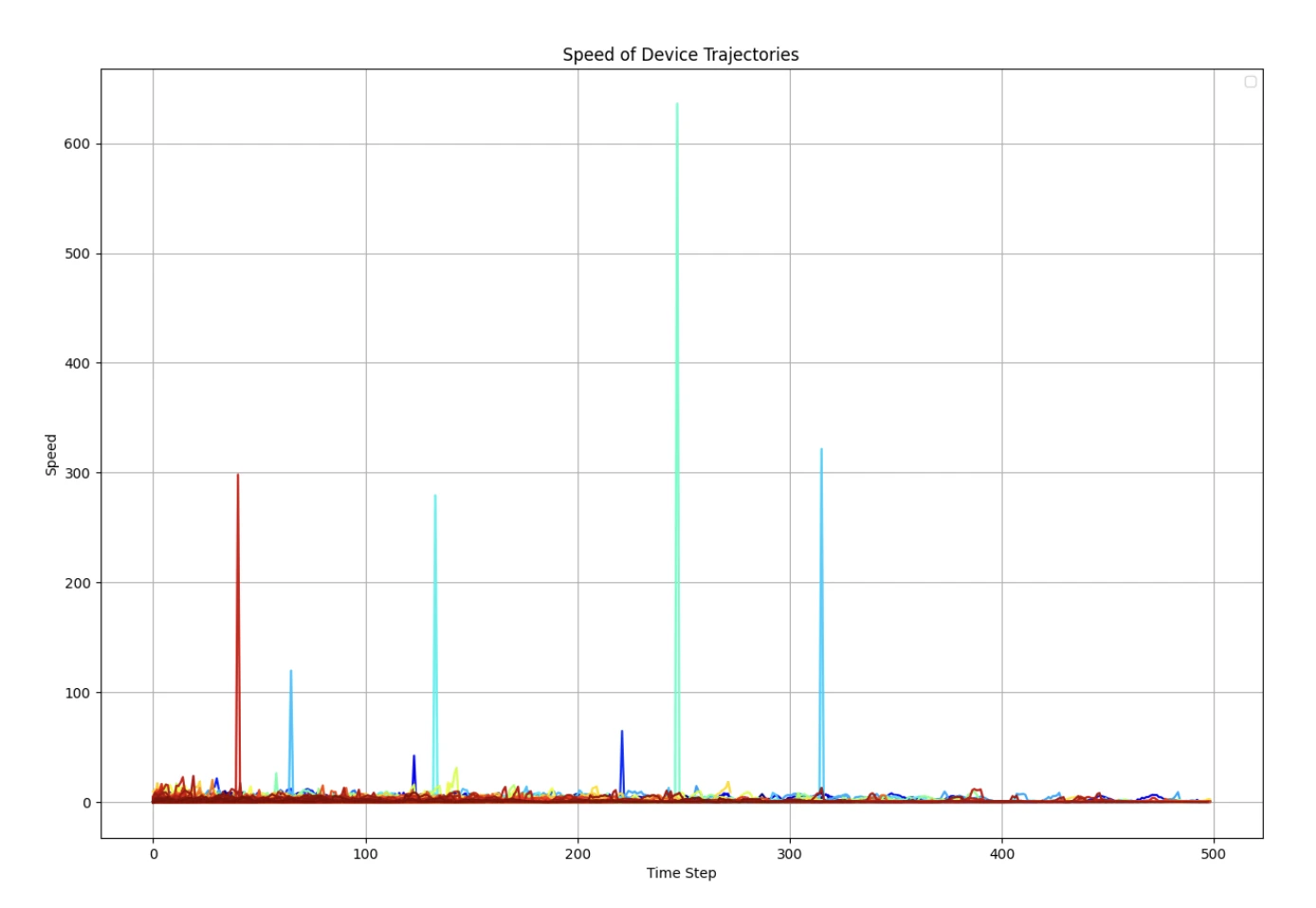
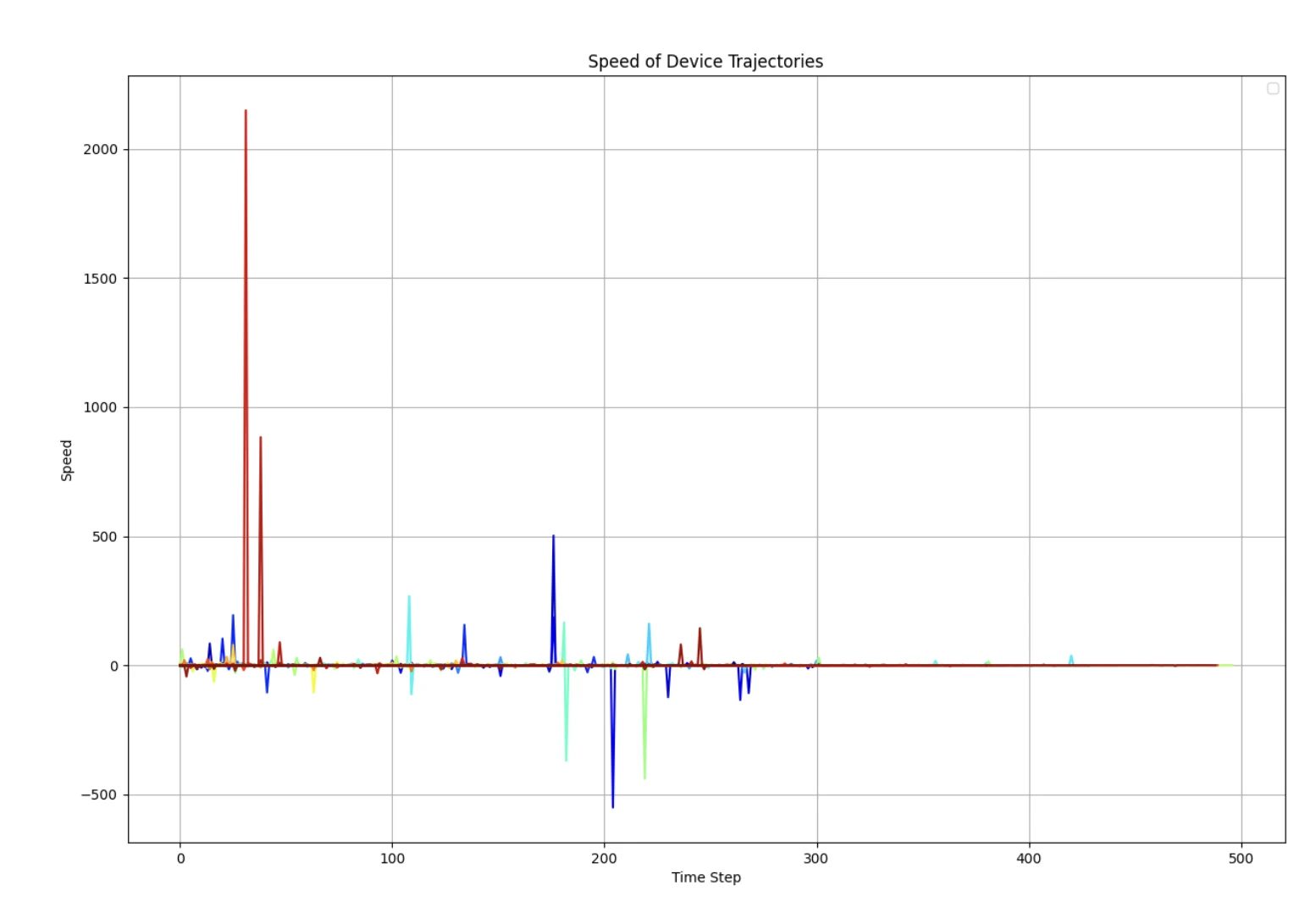
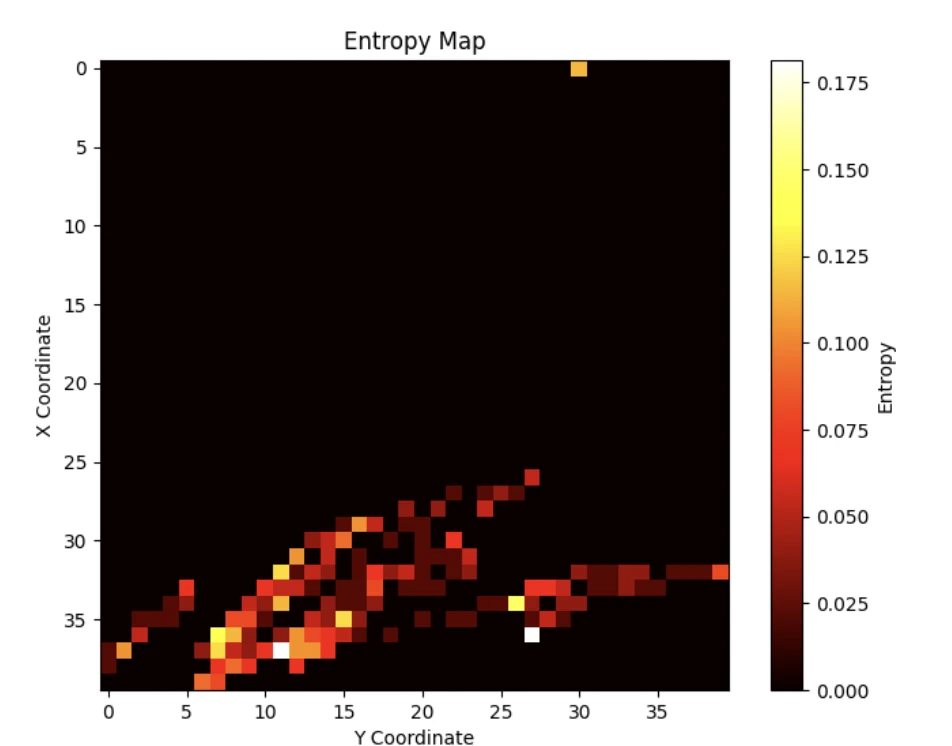
5.2 轨迹墒
能量越高的地方表示数据点越多